研究テーマ
当研究室では,画像・映像を中心としたマルチメディア認識技術の研究を行っています.画像・映像の取得,処理,出力に関する基礎研究から,深層学習(ディープラーニング)を用いたシステム応用まで幅広く扱っています.各研究テーマについての詳細は以下の説明をご覧ください.
大量映像データベースからの検索技術
| 現在,YouTubeに代表されるインターネット上の映像共有サイトには莫大な映像が存在しています.その中からユーザが求めている映像を即座に検索する技術が求められています.当研究室では,単にキーワードを利用した検索ではなく,クエリ文を使用した映像の詳細検索を行う技術に関する研究を行っています.開発したシステムは,米国国立標準技術研究所(NIST)主催の国際競争型映像検索・評価ベンチマーク(TRECVID)において,2016年,2017年,2022年,2023年に世界1位の検索精度を達成しました. |  |
映像からの人物行動推定と異常検知
| 監視カメラ映像で撮影された映像からの人物の行動推定,および,映像の内容を説明する文章を生成する研究を行っています. また,異常な行動や状況を察知し,事故や事件を未然に防ぐための違和感や異常を早期に検知するシステムの検討も実施しています. これらの技術により,人物の行動パターンや行動の意図の推測や,セキュリティや監視業務の向上を目指しています. |  |
着衣やファッションに関する画像認識の応用技術
| 気になっている服の着用イメージを確認するため,服のサイズを調節できる仮想試着の技術や,多様なファッションアイテムの識別とファッションアイテムの関連性を調査する研究を実施しています. また,着物の文様や柄を選ぶ際,その種類を画像認識技術により見分け,その柄の種類や意味を表示できるシステムに関する研究も進めています. |  |
機械学習の技術を歯科医療に活用
| セラミックスのクラウン(被せもの)の製作において,歯の色調の再現は形態の構築と並ぶ重要な要素となっている一方,技術・経験が必要であり,若手歯科技工士の育成が課題となっていました.この課題に対して,機械学習の技術を用いて自動的に色を推定することで,従来ベテラン歯科技工士が担っていた「若手のサポート」を効率的に進め,生産性を向上させることを目指しています. | 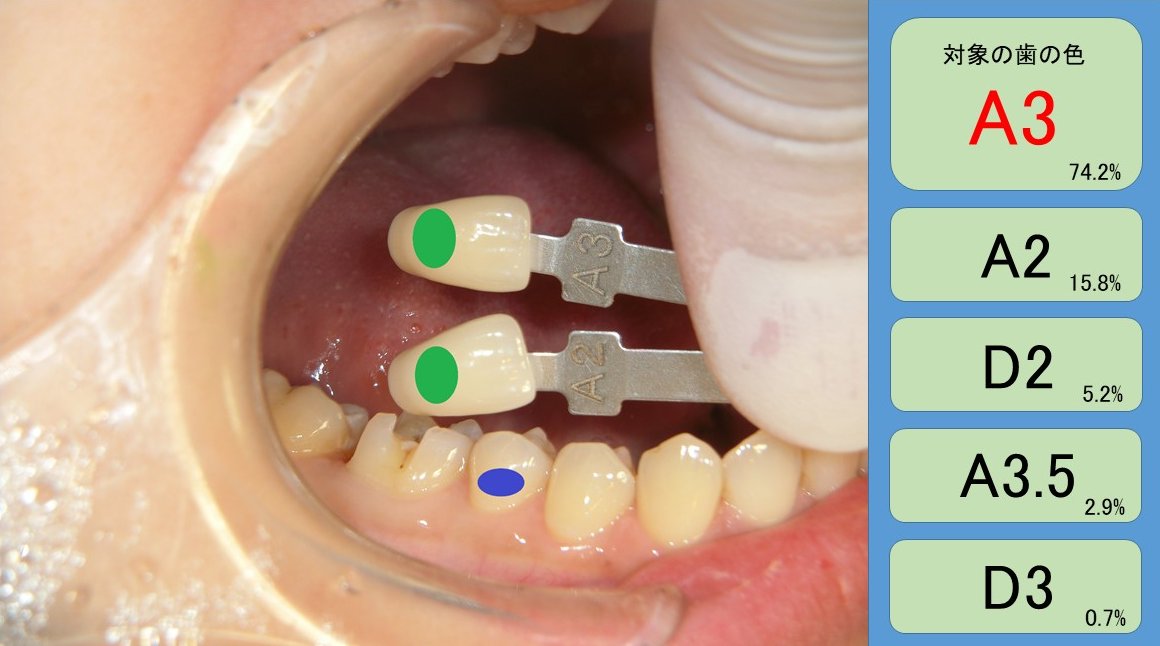 |
セマンティックセグメンテーション技術の実応用
| 近年,深層学習(ディープラーニング)を使うことで,画像中のピクセルがどのクラスのオブジェクトに属しているかをラベリングする技術が大きく発展しています.この技術を用いて,様々な応用システムを検討しています.現在,航空写真からの災害地の復興状況の可視化,車載カメラ映像を用いて動物の急な飛び出しを検出するシステム,車の傷や凹みの検出,精密機器の欠陥検出に関する研究を実施しています. |  |
画像認識技術と人間の感性や感情の融合
|
インターネット上の画像・動画の共有サイトで人気を集めているリミナルスペース※について,画像認識技術と感性工学の理論やモデルを活用して,人々に与える感情や心理的な影響を分析しています.
また,人の顔画像から受ける印象を花、食べ物、動物などモノの種類に例えて表示する研究にも取り組んでいます. ※廃墟や空き地,ショッピングモールの閉鎖時間帯など,人が滞在しない場所や一般的にはアクセスできない場所の映像や写真を指す. |
 |
古典籍の翻刻工程の効率化に向けたくずし字認識
| 歴史的文献の翻刻,電子化の推進のため,人文学オープンデータ共同利用センターが公開している日本古典籍字形データセットを用いて,くずし字の認識を研究しています. 古典文学の翻刻の作業効率化のため,ディープラーニングを用いてひらがな,漢字,カタカナなどの幅広い文字の認識と, 実際の翻刻の場面を想定したシステム構築を検討しています. | 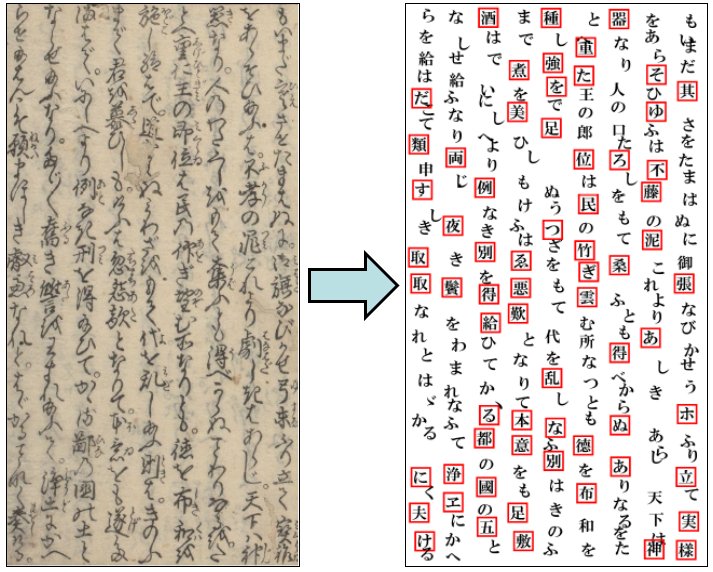 |
ロゴマーク・文字アートの自動作成
| 画像認識技術を活用した文字アートやロゴマークの自動作成に関する研究を進めています. 文字アート作成は,題材となる動物などの絵と文字を入力することで自動的に絵を文字で形作ることができます. ロゴマーク作成は,かっこいい,かわいい,和風,レトロ,ホラーなどの印象語を入力すると,その印象に合ったロゴマークを自動で作成することができます. これにより,デザインの領域における効率性と多様性を向上させ,クリエイティブな表現を促進することを目指しています. |
顔画像認識技術のメイクアップシステムへの応用
| 画像認識技術や機械学習技術を用いて,メイクアップに関連するさまざまな研究を実施しています.メイクアップアドバイザーなしでも,理想の顔に近づくためのメイクアップを自動で支援するためのシステムの構築はその一例です.また,SNS上にアップロードされる化粧品の写真の傾向を分析することにより,化粧品のトレンドを先取りするなどの研究に取り組んでいます. |  |
少量データを用いた画像認識
| 現在,大量の画像サンプルをディープラーニングで学習することで,高精度な画像認識が実現できています.しかしながら,実際の場面において必ずしもデータが大量に収集できるとは限りません.そこで,例えば,植物/動物等の図鑑に載っている画像のように,認識したい対象のカテゴリ数は多く,各カテゴリには1枚の画像しかないという環境下でも,撮影された画像がどのカテゴリかを認識できる手法について研究をしています.現在は,マスコットキャラクターの認識を行うシステムの試作を行いました. |  |
アニメーション・イラスト作成支援
| 手描きアニメーションやイラスト制作における困難な過程や手間のかかる作業を,最新の機械学習技術を活用することで支援できるかを検討しています. これにより,アニメーション・イラスト制作の効率化や時間短縮を実現するとともに,創造性の向上にも寄与することを目指しています. |  |
IoTとビッグデータを活用した未来予測
| 得られるビッグデータを用いて,様々なデータの解析と未来予測を実施したいと考えています.現在は,その一例として,気象衛星画像を用いた天気予測に関する研究を実施しています.将来的には,観測されたデータから災害発生時期の予測を迅速かつ正確に行えるシステムを構築したいと考えています. | 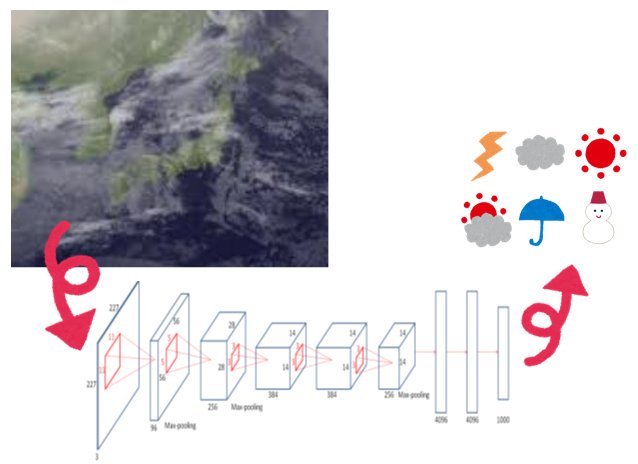 |